Breaking News: Everything Is An Event! (Streams, Kafka And You)
It's about time you met streaming data! I'm sure you two and Apache Kafka will do great things together.
Welcome back! Here's the third article in my series on building streaming apps with Apache Kafka.
The previous article had us build our first real-world streaming application — a real-time fraud detection system.
This time, we'll take a deeper look at some core concepts behind Apache Kafka.
More specifically, we'll try to perform a mind shift. We are used to think in terms of state, but thinking in terms of events allows us to enter the realm of streaming data.
Then, after introducing streams and the streaming data paradigm in greater detail, we'll take a moment to think about why it might be important you become knowledgeable about it.
Spoiler alert: because it's fun to learn, reusable, marketable, and useful to build reactive applications businesses.
Without further ado, let me start your introduction to streaming data.
State and requests
As developers who build apps, data pipelines and data-driven systems, we are used to think in terms of state. We often ask questions such as:
- "Hi, Mailer microservice! Frontend app speaking. Could you send me the list of processed emails for User A so I can update their dashboard?"
- "Hi, REST API! Mailer microservice here. Would you send me the current list of posts, so I can diff it with last week's list and send an update to newsletter subscribers?"
- "Hi, SQL database! I'm the application server. What rows do I have in the
poststable?"
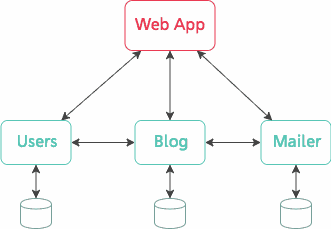
We build complex systems made of many different components and try to wire them up through requests, (or queries, or any communication fitting the request/response paradigm).
Even when we use the latest and shiniest architecture design principles (hint: microservices), we run the risk of ending up with a tightly coupled architecture because components need to know about each other's API in great detail, or need to keep polling one another to detect changes.
Introducing events
There must be a better way
Database queries, API HTTP requests, cache lookups — as far as this article is concerned, all of these are requests that aim at retrieving state. But what do you think the following are?
User created
Tag followed
Post published
Email processed
Draft submitted
Profile updated
These are not requests. These also have nothing to do about state.
This is a plain and simple list of events — mere facts about what just happened in our application or in the outside world. 🏷
We don't always realise that the data we retrieve from storage (like a database or a cache) is only there because something happened in the first place.
That something is an event. But we'll get to it in a moment.
What does an event look like?
An event is a general, abstract concept. One helpful dictionary definition is:
Event: a thing that happens or takes place, especially one of importance.
It may be useful at this point to give you a concrete intuition.
In software, an event is essentially made of two things:
- An action (or label, name, code…) used to clearly identify what happened. For example,
'user_created'or'email_processed'. - Context that provide details and fully determines the event. For example, the first and last name of a newly created user, or the ID of a processed email.
For example, here's one of many possible representations (in JSON) of an event stating that "User 1343 had they first name updated to 'Bob'":
{
"action": "user_updated",
"context": {
"id": 1343,
"field": "first_name",
"previous": "Robert",
"new": "Bob"
}
}
As you can see, an event is simply a fact describing something that happened in the universe.
While seemingly trivial, this idea is at the core of a entirely new paradigm.
The brutal truth
There's a lot to say about events and how they mean and imply different things depending on the field of computing you're working in.
But in my opinion, here's the hard and brutal truth.
Everything is an event, and our ability to harness them is critical to building reactive and performant applications.
If you're not convinced yet, let me give you some examples based on real-world apps you probably already know about.
Arguments from the real world
What do you think applications such as LinkedIn and Slack (no advertising intended) have in common?
All of them produce, harness and process events.
Take LinkedIn for example:
- New job offer? That's an event.
- A notification? That's an event too.
- A profile view? Still an event.
- You updated a skill or your resume? Yet another event!
How about Slack? Well…
- A new direct message? Yup, that's an event.
- Someone created a channel in a workspace? Another event.
- Logged into Slack? Heck — even that is an event!
Anything that LinkedIn or Slack do is process those events in order to create value (whatever that means) to their users. Notice how events can also form a chain: for example, a 'direct_message_received' event will probably trigger a 'notification_created' event.
Anyway, the core idea is that every single thing that happens within an app is an event.
At the beginning of this article, I told you that requests (in the general sense) allow to retrieve state. So if everything is an event, where does state come from?
State, a.k.a persisted events
Events occur at a given point in time. They are ephemeral by nature.
This means that events need to be persisted so you can access them later, i.e. after they happened.
For example, notifications need to be stored in database so you can read them again by the click of a menu.
It turns out that once events are processed and persisted, they become state. From then on, you can retrieve them (or some transformation or aggregation of them) using regular requests.
Let's take an example. For those of you who use Twitter, have you ever noticed how a "Like" you received via a notification may not be counted on the tweet's page until after a few seconds have passed? That's a 'tweet_liked' event being persisted into state — a tweet's counter of likes!
At this point, you may start to realise that, in a sense, state is the consequence of events. An event occurs, you catch it, process it, store it and update state. That's all.
Say "Hello" to streaming data!
When I accepted the truth that everything can be considered as an event, and state simply derives from them, I began to realise there is a completely different paradigm at play here.
This paradigm is that of streaming data.
Instead of thinking about systems exchanging state through requests and response, I started to think about systems exchanging state changes through streams of events.
What is a stream?
Streams have a particular definition in computing:
Stream: a continuous flow of data or instructions, especially one having a constant or predictable rate.
However, I find this definition to be too general. In the context of event streams, we can boil it down to a more specific and more concise form. Here's what I ended up with:
A stream is an unbounded, time-ordered collection of events.
Graphical representations always help, don't they? Here's how you can represent a stream of events as a set of points arranged in a timeline:

To give you an even better intuition of what streams are and what you can do with them, I'd like to take you through an analogy.
The river analogy
Although streams have their own definition in computer science, in everyday language, a stream generally refers to a small river, or at least a flow of liquid.

Image you walk down the riverside. You stop somewhere and watch the water flow past you. There are a lot of observations you can make that have an event stream equivalent:
- Water flows at a rather steady rate → streams are a continuous flow of events.
- Yet, rock formations may locally vary the flow rate → processing rate can vary at various stages of a stream processing pipeline.
- You can count the number of fish swimming in the river → events can be persisted and become state.
- The river results from mulitple, small upstream brooks combined together → streams can have multiple inputs and outputs.
- Large tree trunks retain debris, leaving a clean water downstream → streams can be manipulated through transformations (such as filtering, mapping, etc.).
- etc.
I like this analogy because it gives a general, lively overview of event streams.
But wait a second. So far, we've been talking about streams but didn't say much about how it all fitted within the Apache Kafka ecosystem.
How are streams implemented in Apache Kafka?
Kafka calls itself a distributed streaming platform and implements the streaming data paradigm perfectly. It provides simple yet extremely powerful abstractions to deal with streams of events in a reliable, fault-tolerant manner.
In Kafka, the equivalent of a stream of events is a topic containing messages. A topic is, just like an event stream, a time-ordered collection of messages, with virtually no bounds in the future nor the past — although there is always a first message in a topic and they are generally cleaned up after some time.
Kafka also provides two APIs implementing the publish/subscribe — a.k.a observable/observer — design pattern. They allow topics to have multiple "inputs" and "outputs":
- The Producer API is used to publish events to topics.
- The Consumer API is used to subscribe to topics and process their messages on the fly.
If you're into handy comparison tables, here you go:
| Generic term | Kafka equivalent |
|---|---|
| Event | Message |
| Stream | Topic |
| Publisher | Producer |
| Subscriber | Consumer |
As far as stream transformation (a.k.a. stream processing) is concerned, there's ways to do that in Kafka. 🎉 There are at least two tools for that:
- Kafka Streams: this API provides high-level stream processing capabilities, including mapping, filtering, reducing, windowing, branching, and more. Unfortunately, it is only available for Java and Scala (for now).
- KSQL by Confluent: use plain SQL (and nothing else) to join, aggregate and do windowing on streams in real-time.
However, stream processing is a rather broad area of interest. We might be able to dig into stream processing in Kafka in future posts. I think sticking to a high-level overview is probably enough for the sake of this article.
Why should I care?
We've talked about state and requests vs. events and streams, how everything is an event, what streams actually are and how Kafka implements the streaming data paradigm.
For you, the developer, but also for teams and businesses, why is any of this important anyway?
New possibilities
Streaming data is new paradigm that can open up ideas for new systems, concepts and architectures. It enables an asynchronous, event-driven streaming approach that is entirely different from a more classical synchronous, request-driven batch processing approach.
I also believe it is an exciting opportunity to learn something new and ramp up your skills. When I learnt about Apache Kafka and began to build software with it, I was flabbergasted by how powerful it was — and I loved that it allowed me to build systems communicating via something else than REST APIs and rigid message queues.
Reusable core concepts
Streaming data and event streams are concepts that you can — and may eventually have to — reapply in other areas of software development.
For example, frontend development is going crazy about event streams at the moment. The whole Redux ecosystem (very fashionable among React developers it seems) is based on events triggering a chain of reactions, eventually updating state.
You can also reapply streaming data concepts outside of frontend development. For example, the ReactiveX API and its implementations in various languages — RxJS for JavaScript, RxPy for Python, and more — bring streams and events to many popular languages in the form of "observable streams". Although Rx is mostly used in web development, you're free to use it for projects in other areas too.

Anyway, put in a quotable form:
As tools and frameworks change ever more rapidly, core concepts are here to stay; streaming data is one such core concept.
Advance your career
Being knowledgeable about distributed streaming platforms is actually super marketable.
On January 2nd, 2018, LinkedIn published a report entitled "The Skills Companies Need Most In 2018". Based on job offers activity, they ranked "Cloud and Distributed Computing" and "Middleware and Integration Software" as respectively top 1 and top 3 most needed skills for companies.
Guess what? Distributed streaming platforms like Apache Kafka fall in both of these top skill categories.
Put more casually, Apache Kafka can help you land a job — no less.
I also think that knowing how to use, deploy and design systems interacting with a distributed streaming platform like Apache Kafka is a great skill to have in your toolbox. You'll be able to work across multiple projects and with a lot of different people, which I've always found downright thrilling. 🔥
Scalable systems and teams
Streaming applications with Kafka are multi-tenant, in the sense that a Kafka topic can have multiple producers and multiple consumers.
In particular, this means that increasing throughput generally boils down to a) increasing the number of producers and/or b) increasing the number of consumers. Streaming applications are inherently horizontally scalable.
But there's more to it.
Have you noticed how producers do not have to know anything about who the downstream consumers are? Producers simply push messages to topics, and whoever is interested in them can subscribe to them and do their own processing.
This means that you can have loosely coupled teams working on separate parts of an application. Their interface is exactly defined by the contents of messages — the data is the contract.
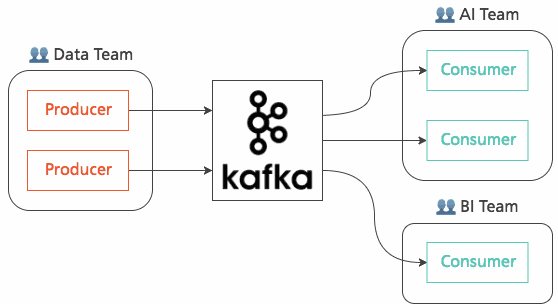
Even better — a new application (say, developed by the BI team) can come and tap into an existing topic without disrupting the flow of other stream processors. Beyond encouraging loose coupling, this property means that streaming applications allow better scaling of teams.
There are many more such benefits of streaming data for human organisations. Here's a last one before we wrap up.
Reactive businesses
As a company, you want your product or services to be able to react to changes in their environment.
A typical way of doing so is batch processing. You build up changes in buffering applications, whose task is to prepare batches to be processed by other systems. However, this way of doing is typically slow both in duration (batches being processed over hours) and frequency (a batch being processed twice or three times a day, but no more).
In contrast, streaming data allows you to process a continuous stream of data. Whatever happens in your system, you can catch it and react to it rapidly. It is then very easy to achieve minute-level reactivity. In the end, streaming data decreases your response time allowing you to wave the killer argument of real-time processing. Boom! 💥
Welcome to a world of streams and events
As we build systems ever more complex, it turns out that the usual request-based approach is not enough to harness events. Instead, a stream is a time-ordered collection of events and an intuitive and efficient way to build reactive applications.
The streaming data paradigm is implemented in Apache Kafka through a set of simple yet powerful abstractions, and I strongly believe you need to become knowledgeable about it.
Wrapping up
I initially planned to write up a final blog post on Apache Kafka's APIs (and perhaps more on cluster deployment), but for various reasons I unfortunately won't have the time to publish them.
This means that this series is coming to an end! Of course, there is way much more to Kafka than I have covered here! We've only scratched the surface. To continue your journey, I've gathered a few great resources for you to enjoy:
- How to use Apache Kafka to transform a batch pipline into a real time one: a thorough example of designing a streaming pipeline, also with a fraud detection example.
- Introduction to Schemas in Apache Kafka with the Confluent Schema Registry: using Avro as a safeguard for your events' formats.
- Real Time UI with Apache Kafka Streaming Analytics of Fast Data and Server Push: example of using Kafka for real-time user interfaces.
- Lessons Learned From Kafka in Production: useful advice and rules of thumbs for configuring a live production Kafka cluster.
- ETL is Dead, Long Live Streams: a case for moving from batch to stream processing, and an experience report of building and scaling a streaming platform.
I also highly recommend you O'Reilly's "Apache Kafka: the Definitive Guide". It helped me a lot in the beginning as it contains a lot of useful background and great guidance on how to set up and configure a cluster, how to monitor Kafka as well as more configuration details on consumers and producers.
Take some time to see how stream processing may be applied to systems you know or you've built, and I'd be happy to hear about the outcome! 🖖💻